
How To Speed Up Your GitLab CI Pipeline
When you first start using CI pipelines you get addicted to them. It’s easy to see why. After all you have made a great improvement to your process and it’s so fast! Soon you start doing more and more and you realize your pipeline is not so fast. It takes 30 minutes!

Waiting 30 minutes for a pipeline to be ready is boring. How can you get more speed? We went through several exercises and figured out a few things.
First let’s define what our pipeline looked like:
Now, let’s go over the 3 key things that changed to improve pipeline speed.
1. Artifacts
On the pack stage we generate some artifacts that need to flow to the next stage, build, which is where we build our container. If you are finding an error that goes something like “artifacts expired” on stages that don't use them, read on.
It turns out that GitLab CI by default grabs artifacts and passes them to the next stage, and the next stage, and the next stage. So if your pipeline is taking too long and your artifact is short lived then you could have extended the life of your artifact, like we did, and that was wrong!
In a big application, downloading the artifacts can mean a significant amount of time. What you want to do is:
This was the biggest offender for us.
2. Cache
Caching for incremental compilation or even for external libraries also helps a lot. We added a cache for every branch with the “key” attribute. We then specified which modules had tests in them so no time was lost looking for test files elsewhere.
Beware! Having too much stuff in the cache can be a big offender too. Those get passed along stages similar to artifacts.
3. Parallel Stages
Our pipeline was huge, we had 5 stages, 2 of those had over 10 parallel jobs, so this step is not to tell you “do parallel jobs” but quite the contrary, beware of parallel jobs.
There is a limited number of parallel jobs a runner can take, so after about 4 all the others get paused and they sit around waiting for a slot. The job itself might be quick but you are adding additional time trying to make it parallel.
Also, setting up the job, downloading anything related to it, performing any before-script sections you might have, takes time. We found it helped to reduce the number of parallel jobs we had in all stages. Just making the most out of the environment that was available at the moment worked well.
So we went from this
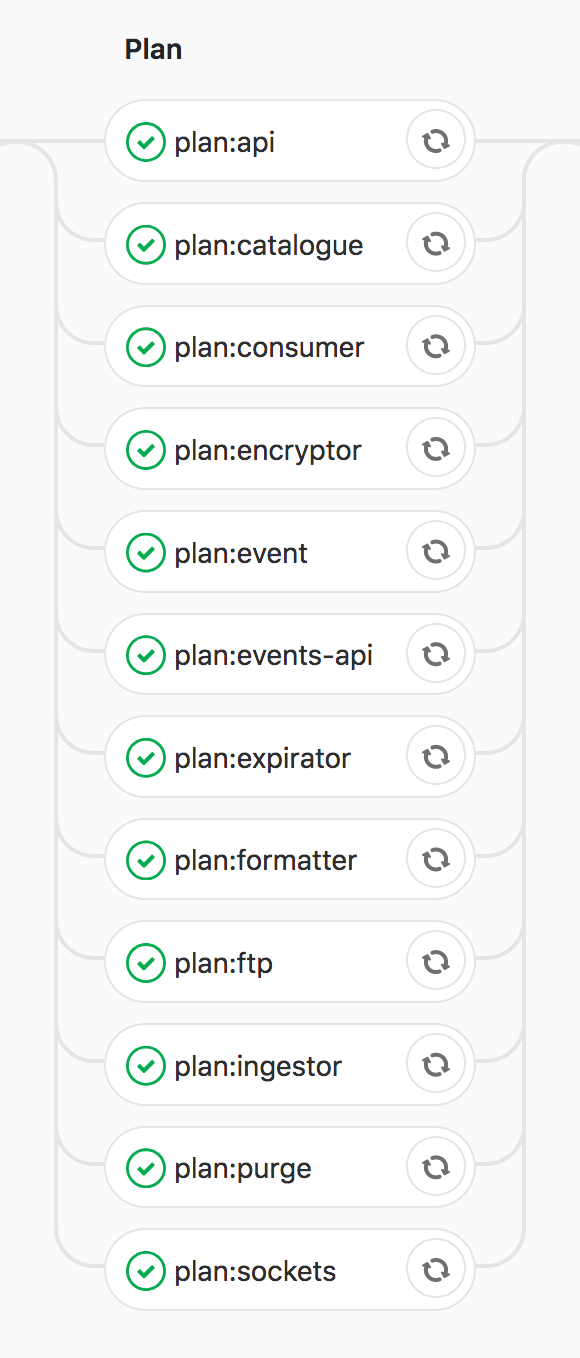
to this
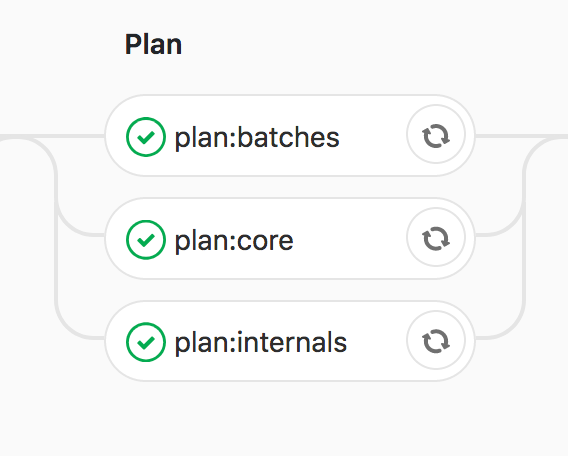
All the same pieces are being planned, we just group them together in a way that made sense for us.
And finally we got to a 75% reduction of the pipeline execution time

Please do read the reference documentation for GitLab-CI and try to find ways to make your pipeline better, there are a lot of new things that are super useful!



